





If you’ve read our articles before, you’ll know that video analytics software like Calipsa’s uses artificial intelligence to identify human activity in images. But how exactly does this work?
Calipsa’s false alarm filtering technology belongs to a field of machine learning known as computer vision. Computer vision employs machine learning techniques to teach computers how to “see” and understand visual information, such as images and video.
Computer vision technology can be applied in different ways to interpret an image; the main applications are classification, detection, and segmentation. Below, we’ll look at each of these techniques and see how they are applied in real-world situations, including in Calipsa’s False Alarm Filtering Platform.
What is image classification?
In image classification, we’re asking a machine learning model to identify what’s in an image, based on labels we have already assigned. The aim is to teach the computer what certain concepts look like, so that it can identify these same concepts in any new images.
To label data, we take a dataset of images and add tags which makes the data meaningful and guides the algorithms on what is most important about the image it’s analysing. After processing enough labelled images, it can successfully predict when the same concepts appear in unlabelled images.
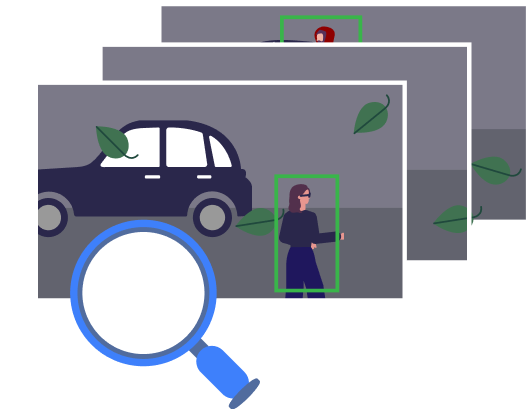
For example, we can label the image below as containing a person and a vehicle. After exposure to thousands of similar labelled images, the model should be able to recognise other images that contain people and vehicles.

Photo by Belle Co from Pexels
What is object detection?
In object detection, we want our machine learning model to identify what an object is and where it to find it in an image. The process of a machine learning model locating objects in an image is known as localisation.
If we now want our model to detect people and vehicles, we can draw bounding boxes around the most important concepts; here, we're labelling the person and the vehicle. By drawing boxes around specific objects, we're telling the model what we want it to predict in unlabelled images. With enough labelled information to learn from, our model should be able to detect people and vehicles in new images, and localise them within boxes.

What is segmentation?
Segmentation is where an image is labelled at a pixel level, which allows for much more detailed identification. With enough information to learn from, a machine learning model can make predictions about each pixel, and then draw on these predictions to precisely recognise and locate an object.
It is extremely important to intelligent video analytics, because the model can ignore what’s going on in the background in order to focus on people and vehicles in the foreground. If we go back to the image above, here is what segmentation of vehicles and people would look like:

The model has learned that the trees, road and buildings are all background, and it has ignored these features in favour of the person and the car, which it has prioritised as objects in the foreground.
In Calipsa’s False Alarm Filtering Platform, we combine these computer vision techniques to identify genuine alarms. By training our machine learning model to understand what human activity looks like, we can help our customers to drastically reduce the volume of false alarms they used to receive.
Want to find out more about how machine learning technology works? Download our ebook, which explains the essentials of machine learning in computer vision.


No comments